Dans la partie cours, nous avons vu la déclaration
<meta charset="utf-8"> et rapidement expliqué sa raison d'être (relire le paragraphe
sur charset dans
cette page).
Les exercices de cette page consistent à prendre un peu plus le temps
de comprendre les effets et le pourquoi de cette déclaration.
Choisir l'encodage.
- Choisir un éditeur de texte.
- Cherchez comment régler l'encodage. Une recherche sur le web pourra être utile,
par exemple il se peut que le choix de l'encodage ne se fasse qu'après avoir sélectionné "enregistrer sous"
(c'est le cas avec gedit sous ubuntu) ou se fasse par les menus de l'éditeur (c'est le cas avec geany ou notepad++).
- Choisir l'encodage utf-8 (c'est le choix par défaut sous linux).
- Tapez le code correspondant à une page html minimale avec le choix du charset fait dans la page de cours (c'est à dire
<meta charset="utf-8">).
- Inscrire dans l'élément body (c'est à dire entre la balise
<body> et la balise </body>) une phrase de votre choix contenant des accents.
- Enregistrez votre fichier.
- Ouvrir votre page avec un navigateur : tout devrait être correct.
- Modifier maintenant la ligne indiquant le charset en :
<meta charset="ISO-8859-1">.
- Ouvrir à nouveau votre page avec un navigateur. Vous devriez constater un problème d'affichage sur les accents.
Pas de solution ici, la démarche doit être suivie comme indiquée dans l'énoncé.
Choisir l'encodage (bis).
- Choisir un éditeur de texte.
- Cherchez comment régler l'encodage.
- Choisir maintenant l'encodage ISO-8859-1 (ou latin-1).
- Tapez le code correspondant à une page html minimale avec le choix du charset
<meta charset="ISO-8859-1">.
- Inscrire dans l'élément body (c'est à dire entre la balise
<body>
et la balise </body>) une phrase de votre choix contenant des accents.
- Enregistrez votre fichier.
- Ouvrir votre page avec un navigateur : tout devrait être correct.
- Modifier maintenant la ligne indiquant le charset en :
<meta charset="utf-8">.
- Ouvrir à nouveau votre page avec un navigateur. Vous devriez constater un problème d'affichage sur les accents.
Pas de solution ici, la démarche doit être suivie comme indiquée dans l'énoncé.
Comprendre l'encodage.
Vous avez constaté avec les exercices précédents
que si l'on demande à un navigateur d'ouvrir une page html,
il faut lui avoir signalé comment a été encodé le texte pour qu'il le lise correctement.
Dans la page de cours,
nous avons expliqué rapidement pourquoi
(relisez cela si nécessaire).
Nous allons maintenant utiliser un éditeur hexadécimal
(par exemple jeex sous ubuntu) pour visualiser cette différence de code.
S'il n'y a pas d'éditeur hexadécimal sur le poste, vous pouvez utiliser l'éditeur hexadécimal en ligne
HexEd
en chargeant le fichier à "analyser" à l'aide du menu "ouvrir"
(ou l'éditeur
Hex Works
en chargeant le fichier à "analyser" à l'aide du menu "open").
Lecture du code de la lettre A en utf-8 et en latin-1.
Avec un éditeur de texte (par exemple gedit, geany, notepad++...),
enregistrer un fichier contenant la simple lettre A.
- Enregistrer une version encodée en utf-8.
- Enregistrer une version encodée en latin-1 (ou ISO-8859-1 ou encore latin-9 ou ISO-8859-15).
- Pour les deux fichiers, l'ouvrir avec un éditeur hexadécimal.
- Quel est le code de la lettre A dans ces deux cas ?
- Combien de bits utilise ce code ? (on pourra chercher confirmation sur le web)
Lecture du code de la lettre é en latin-1 et en utf-8.
Procéder comme ci-dessus pour la lettre é.
Répondez à toutes les questions posées ci-dessus pour la lettre A.
Explication des affichages d'une page web.
A l'aide des codes que vous avez observés et de tables de codage que vous trouverez sur internet,
expliquez les caractères vus dans une page web :
- Dans le cas d'une lettre é codée en utf-8
mais dans une page html comportant la déclaration
<meta charset="ISO-8859-1">
(ou <meta charset="latin-1">).
- Dans le cas d'une lettre é codée en latin-1
mais dans une page html comportant la déclaration
<meta charset="utf-8">.
Lecture du code de la lettre A en utf-8 et en latin-1.
Le fichier
Alatin1.txt
contient la lettre A, l'encodage est ISO-8859-15 (ou latin-9).
Le fichier Autf8.txt
contient la lettre A, l'encodage est utf-8.
Lorsqu'on ouvre le premier fichier avec l'éditeur hexadécimal,
on observe dans la fenêtre principale le code 41 0A.
Une recherche sur le web nous apprend que le code hexadécimal
0A correspond à un "line feed" (saut de ligne),
il s'agit donc simplement d'une marque de fin de ligne.
Le code de la lettre A est le code (hexadécimal)
41 (soit en binaire : 0100 0001 ou encore 65 en décimal).
Ce code occupe 8 bits, soit 1 octet
(comme nous le confirme une recherche sur le web,
par exemple
ici).
Lorsqu'on ouvre le second fichier,
on obtient exactement le même code.
C'est normal : utf-8 a été défini notamment de façon à ce que les codes ASCII soient conservés.
C'est la raison pour laquelle, on n'a pas de problème d'encodage
sur les lettres non accentuées en passant d'un encodage à l'autre.
é codé en utf-8.
Le fichier eacuteUtf8.txt
a été encodé en utf-8 et ne comporte que la seule lettre é.
En ouvrant le fichier avec un éditeur hexadécimal, on constate que é est codé sur 2 octets (16 bits).
Le code hexadécimal est C3 A9, soit 11000011 10101001 en binaire.
é codé en latin-1.
Le fichier
eacuteLatin1.txt
a été encodé en latin-1 et ne comporte que la seule lettre é.
En ouvrant le fichier avec jeex, on constate que é
est codé sur 1 octet (8 bits).
Le code hexadécimale est E9, soit 11101001 en binaire.
Caractères é encodé en utf8 et lu en latin1.
Le fichier eacuteUtf8.html
a été encodé en utf-8 mais le charset déclaré dans l'entête html est
<meta charset="ISO 8859-1">.
Vous pouvez vérifier que les caractères vus en lieu et place de é sont :
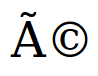 .
.
Si nous cherchons sur le web une table des codes latin1
(par exemple ici),
nous voyons que le code binaire 11000011 (soit C3 en haxadécimal)
correspond au symbole à et que le code binaire 10101001 (A9 en hexadécimal)
correspond au caractère ©.
Nous voyons donc en détail ce qu'il se passe :
utf8 a besoin de 16 bits pour coder la lettre é.
Ces 16 bits correspondent à deux caractères en latin1,
ce sont ces deux caractères qui sont affichés puisque l'on a déclaré à notre navigateur
que l'encodage était latin1.
Caractères é encodé en latin1 (ou latin9) et lu en utf8.
Le fichier eacutelatin.html
a été encodé en ISO 8859-15
mais le charset déclaré dans l'entête html est <meta charset="utf-8">.
En ouvrant ce fichier,
on voit :  .
.
Ce symbole � correspond à un code utf8 non défini.
Il n'y a pas de symbole utf8 correspondant à ce code E9.
Les entités html.
HTML définit des "entités" permettant de représenter des symboles tels que les lettres accentuées. Ces entités étaient nécessaires avant le développement de l'unicode (le code utilisé avec utf8). Avant l'unicode, on utilisait des extensions du code ASCII (American Standard Code for Information Interchange, code sur 1 octet mais n'utilisant que 7 bits et codant uniquement les lettres non accentuées de l'alphabet latin, quelques symboles de ponctuation et quelques caractères spécifiques aux besoins de l'informatique), tel que "ISO-8859-1", qui sont codés sur 8 bits (on utilise le bit non utilisé dans l'octet pour ajouter quelques lettres), ce qui ne permet de ne représenter que 28 caractères, très en-deça du nombre de caractères utilisés dans l'ensemble des langues sur Terre.
Avec la langue française, avec ces codes basés sur ASCII, on utilise (utilisait) donc ISO-8859-1 (latin-1) ou ISO-8859-15 (latin-9). Mais pour d'autres langues (pour lesquelles on aurait besoin d'autres caractères que nos lettres accentuées), il faut utiliser une autre extension du code ASCII. L'utilisation dans une même page de symboles venant de langues différentes est donc difficile avant unicode. Les entités permettent de pallier ce problème.
Exemple : la lettre é peut être obtenue dans une page html par le code d'entité : é.
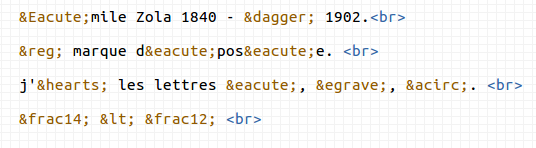
A l'aide de recherches sur le web, écrire le texte ci-dessous sans utiliser de lettres accentuées, ni d'images ou de polices de caractères spéciales dans une page html :
Émile Zola 1840 - † 1902.
® marque déposée.
j'♥ les lettres é, è, â.
¼ < ½
On trouvera facilement une liste des entités html sur le web en tapant "entités html" dans un moteur de recherche.
Par exemple ici et là.